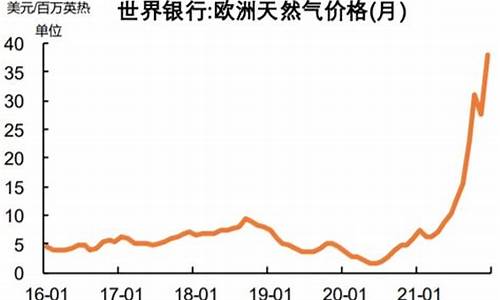
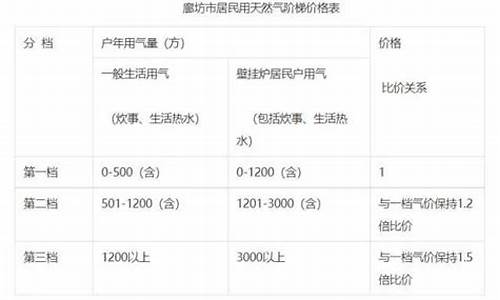
天然气价格预测模型有哪些方法和技巧_天然气价格预测模型有哪些方法
1.大数据在各行各业几乎都站稳了脚跟
2.石油天然气关键参数研究与获取
3.子项目预测结果
4.油气储产量发现趋势预测方法
5.能耗预测技术
6.国外能耗预测概况
7.国内油气趋势预测研究现状
8.应用与效果

预测控制或称为模型预测控制(MPC)是仅有的成功应用于工业控制中的先进控制方法之一。
各类预测控制算法都有一些共同的特点,归结起来有三个基本特征:(1)预测模型,(2)有限时域滚动优化,(3)反馈校正。这三步一般由计算机程序在线连续执行。
预测控制是一种基于预测过程模型的控制算法,根据过程的历史信息判断将来的输入和输出。它强调模型的函数而非模型的结构,因此,状态方程、传递函数甚至阶跃响应或脉冲响应都可作为预测模型。预测模型能体现系统将来的行为,因此,设计者可以实验不同的控制律用计算机仿真观察系统输出结果。
预测控制是一种最优控制的算法,根据补偿函数或性能函数计算出将来的控制动作。预测控制的优化过程不是一次离线完成的,是在有限的移动时间间隔内反复在线进行的。移动的时间间隔称为有限时域,这是与传统的最优控制最大的区别,传统的最优控制是用一个性能函数来判断全局最优化。对于动态特性变化和存在不确定因素的复杂系统无需在全局范围内判断最优化性能,因此这种滚动优化方法很适用于这样的复杂系统。
预测控制也是一种反馈控制的算法。如果模型和过程匹配错误,或者是由于系统的不确定因素引起的控制性能问题,预测控制可以补偿误差或根据在线辨识校正模型参数。
虽然预测控制系统能控制各种复杂过程,但由于其本质原因,设计这样一个控制系统非常复杂,要有丰富的经验,这也是预测控制不能预期那样广泛得到应用的主要原因。
预测控制适用于先进过程控制(APC)和监督控制场合,其控制输出作用主要是跟踪设定值的变化。但预测控制并不能很好地处理调节控制难题。
模型预测控制是一种基于模型的闭环优化控制策略,已在炼油、化工、冶金和电力等复杂工业过程控制中得到广泛的应用。模型预测控制具有控制效果好、鲁棒性强等优点,可有效地克服过程的不确定性、非线性和关联性,并能方便处理过程被控变量和操纵变量中的各种约束。
预测控制算法种类较多,表现形式多种多样,但都可以用以下三条基本原理加以概括:①模型预测:预测控制的本质是在对过程的未来行为进行预测的基础上,对控制量加以优化,而预测是通过模型来完成的。②滚动优化 :预测控制的优化,是在未来一段时刻内,通过某一性能指标的最优化来确定未来的控制作用,这一性能指标涉及到系统未来的行为,并且在下一时刻只施加当前时刻控制作用,它是在线反复进行的,而且优化是有别于传统意义下的全局优化。③反馈校正 :预测控制是一种闭环控制算法,用预测模型预测未来的输出时,预测值与真实值之间存在一定的偏差,只有充分利用实际输出误差进行反馈校正,才能得到良好的控制效果。
目前,预测控制的研究范围主要涉及到以下方面,
(1)对现有基本算法作修正。如引入扰动观测器,用变反馈校正系数等。
(2)单变量到多变量的推广。把只适合于稳定对象的算法推广到非自衡系统,把预测控制的应用范围推广到非线性及分布参数系统。
(3)优化目标函数的选取。如用最小方差的目标函数、二范数的目标函数、无穷范数的目标函数等。
(4)预测模型的选取。尤其是在非线性预测控制中,非线性预测控制要比线性预测控制复杂得多。因而,目前研究主要集中在特殊的非线性模型,如Wiener模型,Bilinear模型、广义Hammerstein模型、Volterra模型等。
(5)引入大系统方法,实现递阶或分散的控制算法。
(6)将基本控制算法与先进的控制思想与结构相结合,如自适应预测控制、模糊预测控制、鲁捧预测控制、神经网络预测控制等。
目前,预测控制的应用几乎遍及各个工业领域,如:炼油、石化、化工、造纸、天然气、矿冶、食品加工、炉窑、航空、汽车等。其中全世界用了以预测控制为核心的先进控制算法已经超过5000多例。国外著名的控制工程公司都开发研制了各自的商品化软件。预测控制的软件产品至今已走过了三代。第一代产品主要以Adersa公司的IDCOM和Shell Oil公司的DMC为代表,可处理无约束的预测控制问题。第二代以Shell Oil公司的QDMC为代表,它增加了处理输入输出有约束的多变量对象的技术。而目前的第三代产品,主要有Aspen公司的DMC plus和Honeywell公司的RMPCT,以及浙大中控软件公司的Adcon等,都已在炼油、化工、石化等工业生产过程中应用。
大数据在各行各业几乎都站稳了脚跟
5.1.1 元素硫沉积预测模型及求解
设条件:
1)地层中流体为气液两相流动,水不参与流动;
2)储层水平、等厚和均质;
3)气体从地层远处径向流入;
4)气井以恒定的产量生产;
5)产量小于临界产量,硫颗粒析出即沉降,堵塞孔隙。
图5.1 平面径向流模型
在上述设的基础上,建立了元素硫沉积预测模型,考虑气体从气藏远处流入井底(见图5.1),当越接近井底时,流动断面面积随之变小,从而导致气体的流速急剧增加。这时由于气体的高速流动,已经不再符合达西定律,可以认为是紊流流动,这种流动被称为非达西流动。因此,不能再利用达西定律来建立元素硫沉积预测模型,必须考虑非达西流动的影响,本章用二项式方程来描述非达西流动:
高含硫气藏工程理论与方法
式中:k——地层渗透率,10-3μm2;
μ——天然气黏度(平均值),Pa·s。
β为描述孔隙介质中紊流影响的系数,称为速度系数,单位是m-1。不同的学者取值各不相同[93~],本章用下式[98]:
高含硫气藏工程理论与方法
设圆形气层中心一口井定量气,任一断面r处的渗流速度等于:
高含硫气藏工程理论与方法
式中:T——气藏温度,K;
Tsc——标况下温度,K;
psc——标况下天然气压力,MPa;
Zsc——标况下天然气压力系数;
Z——天然气压力系数;
p——地层压力,MPa;
v——地层条件下流向井底的气体流速,m/s;
r——地层中任一点距气井中心的径向距离,m;
h——储层的有效厚度,m;
ke——有效渗透率,10-3μm2;
q——天然气地下产量,m3/d;
qsc——天然气地面产量,m3/d;
Bg——气体体积系数。
将(5.3)式代入(5.1)式整理得到:
高含硫气藏工程理论与方法
式中:krg——气体相对渗透率。
设距离井眼中心为r处dt时刻内因压力降落使元素硫在天然气中的溶解度发生变化,并导致含硫气体析出硫的体积量为:
高含硫气藏工程理论与方法
式中:t——生产时间,d;
Vs——元素硫析出的体积量,m2;
ρs——固体硫的密度,2.07g/cm3m3。
元素硫析出占据储层孔隙空间为:
高含硫气藏工程理论与方法
而在dt时刻内由于元素硫的析出在储层含硫气体空间中形成的含硫饱和度为:
高含硫气藏工程理论与方法
式中:Ss——地层气体中的含硫饱和度;
Sw——原始含水饱和度;
φ——储层孔隙度。
将(5.2)式和(5.4)式代入(5.7)式,得到:
高含硫气藏工程理论与方法
为便于计算,令:
高含硫气藏工程理论与方法
其中,ρ为地层流体的密度,由下式计算:
高含硫气藏工程理论与方法
式中:Ma——干燥空气的分子量,28.;
γg——气体的相对密度;
Z——气体的偏差系数(平均值);
R——通用气体常数,0.008315MPa·m3/kmol·K。
对于(2.7)式两边对于压力求导:
高含硫气藏工程理论与方法
将(5.9)、(5.10)式代入(5.8)式,整理得到:
高含硫气藏工程理论与方法
根据文献[20],可得含硫饱和度与气体相对渗透率有如下经验关系式:
高含硫气藏工程理论与方法
将(5.14)式代入(5.13)式得到:
高含硫气藏工程理论与方法
若不考虑非达西项的影响,则描述气体非达西渗流的二项式方程的第二项为零,并由此而得到的(5.13)式中的系数B为零,便可以得到气体达西流动时元素硫沉积的预测模型:
高含硫气藏工程理论与方法
为了分析不同径向距离处,元素硫沉积导致气井堵塞(Ss=1)的时间,分别考虑达西渗流及非达西渗流的情况,对(5.16)式及(5.17)式进行整理分别得到:
高含硫气藏工程理论与方法
5.1.2 考虑元素硫沉积的地层压力变化关系
随着含硫气藏开发的不断进行,地层压力和温度也随之降低,以往的模型都设含硫饱和度不随压力的变化而变化进行计算求解,本章考虑元素硫沉积对渗透率的影响,在定产的情况下,影响地层压力的变化,这样更加符合含硫气藏实际地层压力变化情况。
根据设条件,流动属于稳定流动,在径向上压力降为定值。
高含硫气藏工程理论与方法
对上式两边积分
高含硫气藏工程理论与方法
将(5.2)式代入(5.20)式,整理得到:
高含硫气藏工程理论与方法
式中:pi——原始地层压力,MPa。
通过式(5.21)可以计算得到不同径向距离处压力分布,同时该式考虑元素硫沉积的影响,为了考虑压力在不同径向距离处随时间的变化关系,建立了稳定流动压力在不同径向距离处的计算方程。
5.1.3 考虑压力随时间变化的元素硫沉积模型
以上模型设径向上压力变化为定值,不随时间发生变化,就是设稳定流动。为了完善含硫气藏元素硫沉积预测模型,建立不稳定流动情况下,元素硫沉积导致的储层含硫饱和度随时间的变化模型。
根据基本渗流理论,平面径向不稳定渗流过程中压力分布为:
高含硫气藏工程理论与方法
由于近井地带流速较高,因此必须考虑非达西流动的影响,由于非达西流动只发生在井底的高速气流区,与时间没有关联,考虑非达西流动影响后,(5.22)式整理得到:
高含硫气藏工程理论与方法
其中
高含硫气藏工程理论与方法
将式(5.24)进行单位变换得到式(5.25)
高含硫气藏工程理论与方法
式中:η——导压系数,cm2/s;
ct——岩石压缩系数,1/atm。
将(5.23)式两边对半径r求导,整理得到:
高含硫气藏工程理论与方法
将(5.27)式带入(5.7)式,整理得到含硫饱和度与时间的关系为:
高含硫气藏工程理论与方法
为了方便求解式(5.28),令:
高含硫气藏工程理论与方法
从而得到了方程式(5.13),通过该方程的求解,可以得到不稳定流动状态下,压力随时间的变化关系,进而求出含硫饱和度随时间的变化关系。
石油天然气关键参数研究与获取
大数据时代的到来,改变的不仅仅是传统的商业模式,更深入到人们的生活、工作等各个环节,以及人们的传统观念之中。随着互联网的发展,信息交流也在不断加速,大数据在各行各业几乎都站稳了脚跟,特别是越来越多的机构与公司组织都已经把大数据应用作为了重要的一环。
大数据不仅是一场颠覆性的技术革命,更是一种思维方式、行为模式与治理理念的全方位变革。那么,大数据在社会生活中都有哪些运用与实践呢 在瞬息万变的时代,行业信息也显得愈发重要,数据猿编辑在此为您做详细解析。
大数据助推金融机构的战略转型
随着互联网特别是移动互联网的爆发式增长,未来将迎来一个大数据浪潮。在宏观经济结构调整和利率逐步市场化的大环境下,目前国内的金融机构主要表现出盈利空间收窄、业务定位亟待调整、核心负债流失等问题。而大数据技术正是能够帮助金融机构深入挖掘既有数据,找准市场定位,明确配置方向,推动业务创新的重要手段。
院颁布的《推进普惠金融发展规划(2016-2020年)》中更是直接提到“鼓励金融机构运用大数据、云计算等新兴信息技术,打造互联网金融服务平台。”国内外各金融与类金融机构、互联网金融企业纷纷开始探索大数据的应用,希望大数据可以带来技术与应用上的突破,实现现有风控模型体系的升级,探索基于场景化的新消费金融市场,并提升催收效率、建设互联网深层次大面积获客能力,从而彻底提升国家金融行业的国际竞争力。
大数据提升科技管理系统升级
“在物联网产生之前,或者大的传感器产生之前,我们的集数据来源于访谈、测量或者是记录在纸上,那个时候我们的数据量比较少,而如今,主要靠科学仪器获取大量源源不断产生的数据,数据产生的量非常大,而且复杂度非常高。”正如中国科学院计算机网络信息中心大数据部主任、CODATA中国委员会秘书长黎建辉所言,从手工记录到仪器集,大数据正发生着翻天覆地的变化。
在智能汽车研发方面,重要的一项工作就是大数据分析。福特汽车早已把大数据应用到了公司生产的每一个环节里面,无论是商品的价格、消费者理想的汽车状态,还是公司应该生产的车型以及这种车型购的零部件,抑或汽车应有的设计构造,福特汽车已将大数据应用深入骨髓。车联网时代的到来,让大数据应用于汽车领域越来越广泛。
大数据促进政务大数据共享进程
如今,政务大数据共享还没真正落实,有些部门基于风险考虑而不敢将管理数据拿出来与其他部门共享。主要原因是担心共享会带来负面影响和不利后果,要么害怕共享时暴露出本部门原有数据不真实、不精确而问责,要么认为“数据安全与保密比共享更重要”、取封闭行为更妥当。
大数据时代的到来,给管理变革带来了新的契机。2015年8月院印发《促进大数据发展行动纲要》明确提出“推动数据开放共享”;2016年12月院通过了《“十三五”国家信息化规划》,提出要打破各种信息壁垒和“孤岛”,推动信息跨部门、跨层级共享共用。如何推动部门数据共享,打破信息壁垒和“数据烟囱”,优化管理流程和提升协同治理能力,已经成为当务之急。
大数据加速能源产业发展及商业模式创新
能源大数据理念是将电力、石油、燃气等能源领域数据进行综合集、处理、分析与应用的相关技术与思想。不仅是大数据技术在能源领域的深入应用,也是能源生产、消费及相关技术革命与大数据理念的深度融合,将加速推进能源产业发展及商业模式创新。随着信息化的深入和两化的深度融合,大数据在石油石化行业应用的前景将越来越广阔。
大数据与能源行业的结合目前主要体现在三个行业:(1)石油天然气产业链与大数据的结合。在油气勘探开发的过程中,可以利用大数据分析的方法寻找增长点,利用大数据平台可以帮助炼油厂提高炼化效率,也可帮助下游销售挖掘消费规律,优化库存,确定最佳促销方案。(2)智能电网:利用大数据实时监测技术监测家庭用电量特征,帮助电力公司调配电力供给,为客户提供最佳用电方案。(3)风电行业:进行风电场分布式风机的在线监测,周期性及瞬时的实时数据集和在线分析,生成警报、允许维护人员可视化和管理数据,简化大规模监测系统的部署。
大数据推动天文学、微生物研究迈入新阶段
天文学作为一个典型的大数据应用领域,同样需要通过标准化和一系列规范实现全球的天文科学数据的共享与交易。为了解决国际上天文大数据的开放、共享以及数据间的操作问题,天文学家提出了虚拟天文台的构想,这是一个通过先进的信息技术将全球范围内的研究无缝透明连接在一起而形成的数据密集型网络化天文研究与科普教育平台。
在谈及大数据对天文学方面的贡献时,中国科学院国家天文台信息与计算中心主任崔辰州表示,探索宇宙的奥秘,大数据正在发挥越来越重要的作用。目前,中科院微生物所正在通过研究和开发云环境下微生物数据存储和计算等一系列关键技术,形成完善的微生物数字体系、知识发现平台和大数据服务平台,建立具有国际影响力的微生物数据库,实现我国微生物领域数字建设的突破。
大数据助推国家健康医疗服务新模式
当前,随着经济社会发展和人民生活水平的提高,人民群众在健康方面的需求更加迫切和多元化,这就为健康产业和医疗服务新模式新业态构造创造了良好的生态条件,健康医疗大数据以其广泛的应用性和特殊性未来将对经济发展产生重大贡献,必将成为我国国民经济的重要支柱产业。
据悉,6月20日,国家卫生和生育委员会副主任金小桃透露,组建以国有资本为主体的三大健康医疗大数据集团公司主要是为了落实党中央“没有全民健康就没有全面小康”及“推进健康医疗大数据应用”的精神,落实院办公厅47号文件要求,推动国家健康医疗大数据应用发展。这三大集团将以国家队的形式来承担国家健康医疗大数据中心、区域中心、应用发展中心和产业园建设任务,努力为提高群众获得感、深化医改新动力和增强经济发展新动能作出新贡献。
大数据构建智能交通和推动智慧城市发展
“智能交通”概念的提出,源于日益严重的交通拥堵和出行需求的复杂多元化。但是,在交通数据充足的情况下,如何才能真正让数据变“活” 百度地图的智能路线规划、实时路况、路况预测是交通数据价值的最佳体现。
6月14日,WGDC2017全球地理信息开发者大会进入到第二天,百度地图开放平台总经理李志堂、主任架构师张绍文、内容生态总经理刘斌共同出席“空间大数据+智能交通峰会”,从地图大数据、人工智能导航、数据内容升维表达等角度阐述了百度地图在构建智能交通和推动智慧城市发展中的作用。
大数据让人们的生活更加方便快捷
日常生活中,大数据帮助电商平台打造更极致的用户体验,尤其是网购狂欢节,电商由于提前对消费者需求做了充分调研,因此更能抓住消费者的心理,通过大数据优化产品的质量。而方兴未艾的智慧旅游,避免了旅游旺季各大旅游景点人数太多从而降低游客的好感度,特别是百度大数据通过数据分析,及时了解景区内的状况,帮助游客合理安排出行、提供智能服务。
而据经济之声《天下财经》报道,在今年的亚洲消费电子展上,京东、苏宁等企业携大数据与人工智能,打造智慧物流产业链。伴随着电商行业的迅猛发展,消费型物流需求激增,智慧物流有望成为快递业下一个重要的突破口。这些都必将在一定程度上改变人们的生活,成为大数据带给大家最直接的。
技术的不断更新发展,让数据的价值被重新发现和定义,进而带来整个社会的变革。如今的大数据行业,正显示出朝气蓬勃的生命力,我们在享受这个时代赋予便利的同时,也将对其进行改变与创新。大数据,想说爱你真不容易。
子项目预测结果
评价参数直接影响评价方法的有效性,不同类型的参数作用不同。有效烃源岩有机碳下限、产烃率图版、运聚系数是成因法的关键参数;最小油气田规模对统计法计算结果有较大影响;油气丰度是应用类比法的依据,由已知区带的油气丰度评价未知区带的丰度;可系数是将地质量转化成可量的关键参数。
(一)刻度区解剖
1.刻度区的定义
刻度区解剖是本次评价的特色之一,也是油气评价的重要组成部分。刻度区解剖的目的是通过对地质条件和潜力认识较清楚的地区的分析,总结地质条件与潜力的关系,建立两者之间的参数纽带,进而为潜力的类析提供参照依据。
刻度区是为取准评价关键参数,以保证评价的客观性而选择的满足“勘探程度高、探明率高、地质认识程度高”三高要求的三维地质单元。刻度区可以是一个盆地(凹陷)、一个油气运聚单元、一个区带、一个成藏组合、一个层系或一个二级构造带等。为了正确和客观认识地质条件和潜力,刻度区的选取在考虑“三高”条件的基础上,应尽量考虑不同地质类型的综合,这样可以更充分体现油气丰度与地质因素之间的关系。
2.刻度区解剖内容与方法
刻度区解剖主要围绕油气成藏条件、量及参数三个核心展开,剖析三者之间的关联规律和定量关系。
(1)成藏特征和成藏主控因素分析。成藏特征和成藏主控因素分析实质上是对选择的刻度区进行成藏特征总结,精细刻画出成藏的定性、定量的主控因素与参数,便于评价区确定类比对象。在一个含油气盆地、含油气系统、坳陷、凹陷的成藏规律刻画中,其成藏特征差异大,故一般最好选择以含油气系统(或坳陷)及其间的运聚单元作为对象,更便于有效的类比应用。油气运聚单元是盆地(凹陷)中具有相似油气聚集特征的独立的和完整的石油地质系统,是以盆地(凹陷)的油气聚集带为核心,并包含为该油气聚集带提供油气源的有效烃源岩。油气运聚单元是有效烃源岩、油气运移通道、有效储集层、有效盖层、有效的圈闭等要素在时间和空间上的有机组合。一个油气运聚单元可以有多个有效烃源岩体和烃源岩区为其供烃,但同一个油气运聚单元的油气聚集特征是相似的。一个油气运聚单元可以只包含一个油气成藏组合,也可以包含在纵向上叠置的多个油气成藏组合。因此刻度区地质条件的评价与定量刻画就是按照运聚单元→成藏组合→油气藏的层次路线综合分析烃源条件、储层条件、圈闭条件、保存条件以及配套条件等油气成藏条件。盆地模拟是地质评价流程中的一个重要组成部分,其作用主要体现在三个方面:其一是通过盆地模拟反映流体势特征,进而确定油气运聚单元的边界;其二是提供烃源参数,如生烃强度、生烃量、有效烃源岩面积等;其三是通过关键时刻的获取来反映油气成藏的动态作用过程。
(2)油气量确定。刻度区量计算与一般意义上的量计算稍有不同,正是由于刻度区的“三高”背景,特别是选定的刻度区探明程度越高越好,计算出的量更准确有利于求准各类评价参数。在本次刻度区解剖研究中,主要用了统计法来计算刻度区的量,统计法中包括油藏规模序列法、油藏发现序列法、年发现率法、探井发现率法、进尺发现率法以及老油田储量增长法,不同方法估算出的量用特尔菲加权综合。盆地模拟在计算生烃量方面技术已经比较成熟,因此刻度区(运聚单元)的生烃量仍由盆地模拟方法计算。
(3)油气参数研究。通过刻度区解剖,建立了参数评价体系和预测模型,获得了地质条件定量描述参数、量计算参数和经济评价参数,如运聚系数、丰度等关键参数。从刻度区获得的量与生油量之比可计算出运聚系数,刻度区的量与面积之比可获得单位面积的丰度,还可得到其他参数等。由于盆地内坳陷(凹陷)内各单元成藏条件差异,求得的参数是不同的,故细分若干运聚单元,求取不同单元的参数,这样用于类比区会更符合实际。
3.刻度区研究成果与应用
通过刻度区解剖研究,系统地获得运聚系数、油气丰度等多项关键参数,为油气评价提供各类评价单元类比参数选取的标准,保证评价结果科学合理。如中国石油解剖的辽河坳陷大民屯凹陷级刻度区,通过对其烃源条件、储层条件、圈闭条件、保存条件以及配套条件五方面精细研究,获得了22项量化的成藏条件的系统参数。根据大民屯凹陷内划分的六个运聚单元,分别计算各单元的生油量和量,直接获得六个单元的运聚系数。同时计算出各运聚单元单位面积的量,获得不同成藏条件下的丰度参数(表4-5)。
表4-5 大民屯凹陷刻度区解剖参数汇总表
在中国石油128个刻度区的基础上,各单位根据评价需要,又解剖了一定数量的刻度区。其中,中国石油利用已有刻度区128个,新解剖刻度区4个,共应用132个;中石化新解剖42个;中海油新解剖4个;延长油矿新解剖3个。各项目共应用了181刻度区,这些刻度区涵盖了我国主要含油气盆地中的大部分不同类型的坳陷、凹陷、运聚单元和区带,基本满足了不同评价区的需要。各种类型刻度区统计见表4-6。
表4-6 各种类型刻度区统计表
(二)有效烃源岩有机碳下限
有效烃源岩有机碳下限是指烃源岩中有机碳含量的最小值,小于该值的烃源岩生成的烃量不能形成有规模的油气聚集。有效烃源岩有机碳下限是确定烃源岩体积的主要参数,直接影响生烃量的计算结果。
在大量烃源岩样品分析化验和有关地质资料研究基础上,明确了不同岩类有效烃源岩有机碳下限标准。陆相泥岩有效烃源岩有机碳下限为0.8%,海相泥岩为0.5%,碳酸盐岩为0.2%~0.5%,煤系源岩为1.5%。例如,陆相泥岩TO C与S1+S2关系表明,S1+S2在TO C为0.8%时出现拐点,有效烃源岩有机碳下限定为0.8%;碳酸盐岩气源岩残余吸附气量与有机碳关系表明,残余吸附气量在有机碳为0.2%处出现拐点,有效烃源岩有机碳下限定为0.2%(图4-1、图4-2)。
图4-1 陆相泥岩TOC与S1+S2关系图
图4-2 碳酸盐岩气源岩残余吸附气量与有机碳关系图
对于勘探实践中已经发现油气藏,但烃源岩有机碳含量未达统一下限的盆地,根据实际情况可进行适当调整。如柴达木盆地柴西地区,在分析了大量烃源岩有机碳和S1+S2指标资料后,明确该区有机碳含量下限为0.4%时,即达到有效烃源岩标准,并被发现亿吨级尕斯库勒大油田的勘探实践所证实。在渤海湾盆地评价过程中,建立起相对统一的有效烃源岩丰度取值下限标准:碳酸盐岩气源岩丰度下限取0.2%,碳酸盐岩油源岩丰度下限取0.5%,湖相泥岩丰度下限取1.0%。
有效烃源岩有机碳下限的基本统一,保证了生烃量计算标准的相对一致和全国范围内的可比。
(三)产烃率图版
烃源岩产烃率图版是用盆地模拟方法计算烃源岩生烃量和量的关键参数。产烃率图版一般用烃源岩热模拟实验方法获得。
1.液态烃产率图版
利用密闭容器加水热模拟实验方法,对中国陆相盆地不同类型烃源岩进行了热模拟实验。模拟实验所用样品取自松辽、渤海湾等10个盆地,包括侏罗系、白垩系和古近系的湖相泥岩、煤系泥岩和煤3大类烃源岩。其中湖相泥岩烃源岩的有机质类型包括Ⅰ型、Ⅱ1型、Ⅱ2型和Ⅲ型,煤系泥岩烃源岩的有机质类型包括Ⅱ2型和Ⅲ型,煤烃源岩的有机质包括Ⅱ1型、Ⅱ2型和Ⅲ型。根据模拟实验结果,编制了不同类型烃源岩的液态烃产率图版(图4-3、图4-4、图4-5)。
图4-3 湖相泥岩烃源岩液态烃产率图版
图4-4 煤系泥岩烃源岩液态烃产率图版
图4-5 煤烃源岩液态烃产率图版
2.产气率图版
由于生物气生气机制与干酪根成气和原油热裂解气的生气机制不同,因此,其产气率与干酪根和原油裂解气产气率求取方式不同。
(1)生物气产气率。对生物气源岩样品在25℃~75℃的条件下进行细菌培养产生生物气,由此得到不同温阶下各类有机质的生物气产率。在模拟实验结果的基础上,结合前人的研究结果,分别建立了淡水环境、滨海环境和盐湖环境中不同类型有机质的生物气产气率图版及演化模式。
(2)干酪根和原油裂解气产气率。对于不同类型气源岩油产气率,国内外学者及一、二轮评价中已做过大量的工作。较多的实验是应用热压模拟方法对各种类型烃源岩进行产油及产气率实验,这种方法所计算的产气率包括了原油全部裂解成气的产率,亦即常说的封闭体系下源岩的产气率,所得到的天然气产率是气源岩的最大产气率。另一种求取气源岩产气率的方法是在开放体系下对源岩进行热模拟实验,各阶段生成的天然气和原油均全部排出源岩,原油不能在源岩中进一步裂解为天然气。这两种情况都是地质中的极端情况。但是实际的地质条件大多是半开放体系,在这种情况下,源岩生成的油既不能全部排出烃源岩,也不能完全滞留于源岩中。不同地质条件下亦即开放程度不同情况下源岩产气率如何计算?具体方法为:求得封闭和开放体系下相同类型源岩的产气率,将上述两种体系下的产气率图版(中值曲线)输入盆地模拟软件中,得出烃源岩层在不同渗透条件下产气率图版。
(四)运聚系数
运聚系数是油气聚集量占生烃量的比例,是成因法计算量的一个关键参数,直接影响量计算结果。运聚系数的确定方法包括运聚系数模型建立法和运聚单元成藏条件分析法。
1.运聚系数模型建立法
通过刻度区解剖,确定影响运聚系数的主要地质因素及其与运聚系数的相关关系。刻度区解剖研究表明,烃源岩的年龄、成熟度、上覆地层区域不整合的个数和运聚单元的圈闭面积系数等地质因素与石油运聚系数之间存在相关关系。依此建立地质因素与石油运聚系数之间关系的统计模型,包括双因素模型和多因素模型。双因素模型(相关系数为0.922)的地质因素选用烃源岩年龄和圈闭面积系数:
lny=1.62-0.0032x1+0.01696x4
多因素模型(相关系数为0.934)的地质因素选用烃源岩年龄、烃源岩的成熟度、区域不整合个数和圈闭面积系数:
lny=1.487-0.00318x1+0.186x2-0.112x3+0.02118x4
式中:y——运聚单元的石油运聚系数,%;
x1——烃源岩年龄,Ma;
x2——烃源岩成熟度(Ro),%;
x3——不整合面个数;
x4——圈闭面积系数,%。
2.运聚单元成藏条件分析法
依据刻度区提供的大量运聚系数,依盆地类型和影响运聚系数的主要地质因素,分类建立运聚系数取值标准与应用条件。在评价中,根据刻度区解剖结果,确定了油气运聚系数分级取值标准(表4-7)。在评价中得到了推广应用,取得了良好的效果。
表4-7 石油运聚系数分级评价表
(五)最小油气田规模
最小油气田规模是指在现有工艺技术和经济条件下开地下,当预测达到盈亏平衡点时的油气田可储量。最小油气田规模对统计法计算的量结果有较大影响。为此,中国石油天然气集团公司等三大石油公司和延长油矿管理局对最小油田规模进行了专门研究。
通过对不同油价、不同开发方式和未来可能技术条件下最小油气田规模研究,确定了不同地区的最小油气田规模的取值。在地理环境相对较好的东部地区,其勘探开发成本较低,最小油气田规模一般在10×104~30×104t,在地理环境相对较差的西部地区,其勘探开发成本高,最小油气田规模一般在50×104t以上,对于海域来说,油气勘探开发成本更高,最小油气田规模更大,一般在150×104~500×104t。
(六)丰度
油气丰度是指每平方公里内的油气量,是类比法计算量的关键参数。通过统计分析,建立了丰度模型和取值标准。
1.丰度模型
通过刻度区解剖,建立刻度区内评价单元油气丰度和相关地质要素之间的统计预测模型:
新一轮全国油气评价
式中:y——运聚单元的石油丰度,104t/km2;
x1——烃源岩生烃强度,104t/km2;
x2——储集层厚度/沉积岩厚度,小数;
x3——圈闭面积系数,%;
x4——不整合面个数。
2.丰度取值标准
通过统计不同含油气单元丰度的分布特点,结合地质成藏条件,总结出各类刻度区丰度的取值标准。
(1)不同层系丰度:古近系凹陷由于成藏条件优越,成藏时间晚,石油地质丰度一般大于20×104t/km2;中生代凹陷成藏时间相对较长,石油地质丰度相对较低,一般约为10×104t/km2;古生代凹陷由于生、储层时代老,多期成藏多期改造、破坏,预计其丰度更低。
(2)不同类型运聚单元丰度:中新生代断陷或坳陷盆地长垣型、潜山型和断陷型中央背斜构造型,石油地质丰度高,一般大于40×104t/km2;中新生代裂陷盆地、坳陷盆地边缘构造型和古近系缓坡构造型石油丰度次之,一般为10×104~30×104t/km2;中生代盆地岩性型和古生代压陷盆地的构造型石油丰度相对较低,一般小于10×104t/km2。
(3)不同区块或区带级丰度:区块或区带级石油丰度差异更大,从小于1×104t/km2到大于200×104t/km2。其中潜山型、岩性—构造型、披覆背斜区块丰度较高,一般大于50×104t/km2,最大可大于200×104t/km2。构造—岩性型、断裂构造型丰度一般为30×104~50×104t/km2。地层—岩性型、断鼻型以及裂缝型区块、丰度较低,一般小于30×104t/km2。
通过刻度区解剖标定多种成藏因素下评价单元的丰度,不但为广泛应用类比法计算量提供了可靠的参数,同时也摆脱了过去以盆地总量为基础,利用地质评价系数类比将量分配到各评价单元的做法,使类比法预测的油气量在空间位置上更准确,提高了油气空间分布的预测水平。
(七)可系数
国外主要用建立在类比基础上的统计法计算油气可量,而我国第一轮、第二轮全国油气评价没有计算油气可量。本轮评价开展的油气可系数研究,通过可系数将地质量转化为可量,这在国内外油气评价中尚属首次。可系数是指地质中可出的量占地质量的比例,是从地质量计算可量的关键参数。
可系数研究与应用是常规油气评价的重要组成部分,主要目的是通过重点解剖、统计和类析方法,对我国油气可系数进行研究,为科学合理地计算油气可量提供依据,进而对重点盆地和全国油气可潜力进行评价。
1.评价单元类型划分
为使可系数研究成果与评价单元划分体系有机结合,遵循分类科学性、概括性和实用性三个基本原则,以油气类型、盆地类型、圈闭类型、储层岩性、储层物性等地质因素为依据,对评价单元进行了分析和分类,将国内石油评价单元分为中生代坳陷高渗、古近纪与新近纪断陷盆地复杂断块高渗等24种类型,天然气评价单元分为克拉通盆地古隆起、前陆盆地冲断带等16种类型(表4-8、表4-9)。
表4-8 不同类型评价单元石油可系数取值标准
表4-9 不同类型评价单元天然气可系数取值标准
2.刻度油气藏数据库的建立
已发现油气赋存在油气藏中,建立刻度油气藏数据库是统计已发现油气收率、分析影响收率主控因素、预测油气可系数的基础。刻度油气藏是油气可系数研究中作为类比标准的,地质认识清楚、开发程度高、已实施二次油或三次油技术的油气藏。
刻度油气藏选择原则:①典型性——能代表国内外主要的油气藏类型,保证类比法应用基础的广泛性;②针对性和实用性——针对油气评价,有效地指导相应类型评价单元油气可系数的确定;③开发程度高——油气藏开发程度高,地质参数和开发参数基本齐全;④三次油技术应用具有代表性——尽量选择已实施三次油技术的油藏,保证技术可系数的可靠性。
对国内43个油藏、30个气藏,国外59个油藏、22个气藏进行了剖析:收集整理每个油气藏的主要地质和开发参数;每个油气藏的地质条件主要包括储层特征、圈闭条件、流体性质等,开发条件主要包括开方式、开速度、增产措施等;研究不同因素对收率的影响程度,进而确定该油气藏收率的主控因素;针对开方式的不同,油藏的收率可分为一次、二次或三次收率;气藏主要是一次收率。通过对每个油气藏的地质条件、开发条件和收率进行分析,建立起国内外刻度油气藏数据库。
3.可系数主控因素分析
对影响可系数的地质条件、开发条件和经济条件进行了分析,建立起可系数主控因素的评价模型。
(1)在大量统计和重点解剖的基础上,对油气地质条件中的因素逐一进行分析,并提炼出15项油气收率的主控因素,即盆地类型、储层时代、圈闭类型、沉积相类型、储层岩性、储层厚度、储集空间类型、孔隙度、渗透率、埋深、含油饱和度、原油粘度、原油密度、变异系数、原始气油比。
(2)在诸多开发条件中,提高收率技术是极为重要的因素,不同提高收率技术适用条件不同,其提高收率的潜力也差距很大。通过综合分析,主要技术对不同类型油藏的提高收率潜力为:最小5%,中间值10%,最大值15%。
(3)利用石油公司提高收率模拟研究成果,建立了大型背斜油藏、复杂背斜油藏、断块油藏、岩性油藏、复杂储层油藏等在税后内部收益率为12%、油田开发到含水95%时聚合物驱和化学复合驱油时的油价与油田收率之间的关系,若这五类油藏要达到相同的收率,条件好的如大型背斜油藏、复杂背斜油藏所需的油价低于条件差的如岩性油藏、复杂储层油藏。
4.可系数取值标准的建立
在研究中,解剖了国内43个油藏、30个气藏,国外59个油藏、22个气藏,统计分析了大量油气田收率数据,给出了不同类型评价单元油气技术可系数和经济可系数取值范围,建立了不同类型评价单元油气可系数取值标准(表4-8、表4-9)。
(1)不同类型评价单元石油可系数相差较大,以技术可系数为例:中生代坳陷高渗和古近纪与新近纪断陷盆地复杂断块高渗评价单元可系数最大,其中间值大于40%;中生代坳陷中渗、古近纪与新近纪断陷盆地复杂断块中渗、中生代断陷、中新生代前陆、古生界潜山、古生界碎屑岩、古近纪残留型断陷、陆缘裂谷断陷古近纪与新近纪海相轻质油、陆缘弧后古近纪与新近纪海陆交互相轻质油等评价单元可系数为30%~40%;中生代坳陷低渗、古近纪与新近纪断陷盆地复杂断块低渗、古生界缝洞、南方古近纪与新近纪中小盆地、低渗碎屑岩、重(稠)油中高渗、变质岩、砾岩、陆内裂谷断陷新近纪重质油、陆内裂谷断陷古近纪复杂断块等评价单元可系数为20%~30%;低渗碳酸盐岩、重(稠)油低渗、火山岩等评价单元可系数为15%~20%。
(2)不同类型评价单元天然气可系数相差也较大:克拉通碳酸盐缝洞、礁滩和前陆冲断带等评价单元可系数最大,其平均值大于70%;克拉通古隆起、克拉通碎屑岩、前陆前渊、南方中小盆地、陆缘断陷、火山岩、变质岩和海域古近纪与新近纪砂岩等评价单元可系数为60%~70%;前陆斜坡、生物气、中生代坳陷、古近纪与新近纪断陷盆地复杂断块、残留断陷、砾岩等评价单元可系数为50%~60%;致密砂岩等评价单元可系数最小,其平均值小于50%。
5.可系数计算方法的建立
可系数计算方法包括可系数标准表法和刻度区类比法两种方法。
(1)标准表取值法。利用可系数标准表求取不同评价单元可系数的步骤如下:在不同类型评价单元可系数取值标准表中找到已知评价单元的所属类型;明确评价单元与可系数相关因素(宏观、微观)的定性、定量资料;对照可系数的类比评分标准表和类比评分计算方法,对评价单元进行类比打分;根据类比评价结果求取可系数。
(2)刻度区类比法。以建立的国内外刻度油气藏数据库为基础,利用刻度区类比法来求取不同评价单元的可系数。具体步骤如下:根据评价单元分类标准,将具体评价单元归类,并分析整理该评价单元的油气地质条件和开发条件;根据评价单元的类型及其地质条件和开发条件,从国内外刻度油气藏数据库选择适合的类比对象;对照可系数的类比评分标准表和类比评分计算方法,对该评价单元及其类比对象进行打分并计算它们的得分差值;根据得分差值求取该评价单元的可系数。
通过油气可系数标准和计算方法在全国129个盆地中的推广应用,既检验了可系数取值标准和所用基础数据的可靠性、可行性和适用性,保证了油气可量计算的客观性,又获得了全国油气可量。
油气储产量发现趋势预测方法
一、子项目概况
“我国油气潜力分析及储量、产量增长趋势预测”项目由新一轮全国油气评价项目办公室组织,国土部油气战略研究中心、中国石油大学(北京)、中国石油天然气集团公司(简称“中石油”)、中国石油化工集团公司(简称“中石化”)、中国海洋石油总公司(简称“中海油”)和青岛海洋地质研究所等单位共同参加,形成产、学、研相结合的工作方式,充分利用新一轮全国油气评价已进行评价工作的基础和成果,开展油气发现趋势预测研究。
项目共分5个子项目:
(1)中石油负责矿权区内Ⅰ类和Ⅱ类盆地2006~2030年油气储量、产量的增长趋势。
(2)中石化负责矿权区内Ⅰ类和Ⅱ类盆地2006~2030年油气储量、产量的增长趋势。
(3)中海油负责矿权区内Ⅰ类和Ⅱ类盆地2006~2030年油气储量、产量的增长趋势。
(4)青岛海洋地质研究所负责预测海域其他盆地2006~2030年油气储量、产量的增长趋势。
(5)中国石油大学(北京)负责制定统一的评价方法体系与参数标准,以及趋势预测软件的研制和数据库的建立,预测陆上其他盆地2006~2030年油气储量、产量的增长趋势。
二、中石油趋势预测结果
(一)工作范围
对已有油气田开发的8个Ⅰ类盆地和已发现油气田的6个Ⅱ类盆地进行重点研究和详细解剖,预测盆地或一级构造单元储量和产量在2006~2030年的增长趋势;对4个有少量油气产量或探明储量的Ⅲ类盆地和81个有油气远景的Ⅳ类盆地通过类析其储量和产量增长趋势。
(二)预测方法
在对18种预测方法的内涵、特点及使用条件分析研究基础上,选择翁氏旋回模型、HCZ模型、哈伯特模型与龚帕兹模型等四种方法对中石油未来石油、天然气储量的增长趋势进行预测。翁氏模型法和HCZ模型法两种方法的预测结果比较接近,而且增长高峰期过后,储量下降速度与勘探实际比较吻合;哈伯特模型法和龚帕兹模型的预测结果偏乐观,储量增长高峰期也偏晚,且高峰过后储量下降速度偏快,与实际的储量增长过程吻合性较差。因此,对未来25年油气储量增长趋势的预测,主要依据HCZ和翁氏模型方法确定。
对中石油未来石油、天然气产量趋势的预测方法主要选择了模型预测和储比控制两大类方法进行,其中模型预测法的选择借鉴了储量预测方法选择的思路,主要选用了HCZ模式、翁氏模型、哈伯特模型与龚帕兹模型等四种方法。储比控制预测法是在对预测期内新增动用可储量的预测基础上,用剩余可储量的储比作为控制条件进行产量预测的一种方法。
另外,中石油还使用了专家评估法进行了部分盆地的预测。
(三)预测结果
依据多种预测方法获得的数据,结合对石油勘探储量增长趋势的分析,对预测结果作适度调整,综合给出未来25年中石油的石油、天然气储量、产量增长趋势,列于表3-1-1、表3-1-2;图3-1-1、图3-1-2。
各个盆地的具体预测结果如表3-1-3~表3-1-6。
表3-1-1 中石油探明石油地质储量增长趋势预测结果表
表3-1-2 中石油天然气地质储量增长趋势预测结果对比表 单位:108m3
注:5年新增可储量/年均新增可储量。
图3-1-1 储比控制法中国石油常规原油产量构成图
图3-1-2 中国石油气层气产量构成图
表3-1-3 盆地每五年年均石油储量预测结果表 单位:108t
表3-1-4 盆地每五年年均石油产量预测结果表 单位:104t
表3-1-5 盆地每五年年均天然气储量预测结果表 单位:108m3
表3-1-6 盆地每五年年均天然气产量预测结果表 单位:108m3
三、中石化趋势预测结果
(一)工作范围
1.已有油气田并规模开发的4个Ⅰ类盆地
承担济阳坳陷、东濮凹陷、塔里木盆地和东海西湖凹陷4个重点盆地、凹陷的预测工作。
2.已有油气田的3个Ⅱ类盆地
承担江汉盆地、南襄盆地、苏北盆地等3个盆地的预测工作。
(二)预测方法
对石油探明储量的预测主要选用逻辑斯谛、龚帕兹、哈伯特和多旋回哈伯特模型三种模型;除了时间序列法之外,通过系统收集、整理预测区历年石油探井井数、探井进尺、单井发现率和单位进尺发现率数据,使用单井发现率法和单位进尺发现率法进行油气储量的预测。取时间序列法和勘探效益法两种方法预测结果的平均值作为最后推荐值。
使用“储量—产量”双控模型预测石油产量,即根据预测区石油新增地质储量规模、新增地质储量动用率、新增地质储量收率、未来提高收率潜力和储比的可能取值,由“储量—产量”双控模型,计算出今后各时期石油产量的预测值。
(三)预测结果
依据多种预测方法获得的数据,结合对石油勘探储量增长趋势的分析,对预测结果作适度调整,综合给出未来25年中石化各个盆地的石油、天然气储量、产量预测趋势,列于表3-1-7~表3-1-10。
表3-1-7 中石化各盆地每五年年均石油储量预测结果表 单位:108t
表3-1-8 中石化各盆地每个五年末石油产量预测结果表 单位:104t
表3-1-9 中石化各盆地、坳陷每五年年均天然气储量预测结果表 单位:108m3
表3-1-10 中石化各盆地每个五年末天然气产量预测结果表 单位:108m3
四、中海油趋势预测结果
(一)工作范围
1.已有油气田并规模开发的4个Ⅰ类盆地
承担渤海湾盆地(海域)、珠江口、莺歌海、琼东南4个重点盆地的预测工作。
2.已有油气田的1个Ⅱ类盆地
承担北部湾盆地1个盆地的预测工作。
3.有油气远景的2个Ⅳ类盆地
承担南黄海盆地、台西—台西南盆地预测工作。
(二)预测方法
本次油气发现趋势预测在中高勘探程度的盆地以统计法为主,在中低勘探程度的盆地以类比法为主。
石油储量预测的统计法主要选用龚帕兹、HCZ、广义翁式旋回三种模型。产量预测除了以上三种模型,还使用“储量—产量”双控模型。
对天然气的预测主要依据2005年编制的中国近海2050年天然气远景规划,其中根据近期深水勘探进展对珠江口盆地进行了调整。
(三)预测结果
依据多种预测方法获得的数据,结合对石油勘探储量增长趋势的分析,对预测结果作适度调整,综合给出未来25年中海油的石油、天然气储量、产量预测趋势,列于表3-1-11~表3-1-15。
表3-1-11 中海油各盆地每五年年均石油储量预测结果表 单位:108t
表3-1-12 中海油各盆地每五年年均石油产量预测结果表 单位:108t
表3-1-13 中海油每五年年均天然气储量预测结果表 单位:108m3
表3-1-14 中海油每五年年均天然气产量预测结果表 单位:108m3
五、青岛所趋势预测结果
(一)工作范围
开展我国其他海域盆地(指目前石油公司探区以外海域或盆地,包括北黄海盆地、冲绳海槽盆地、曾母盆地、万安盆地、文莱—沙巴盆地、西北巴拉望盆地、北康盆地、中建南盆地、南薇西盆地、礼乐盆地、笔架南盆地、南沙海槽盆地、南薇东盆地、永暑盆地、安渡北盆地及九章盆地共16个盆地)油气发现趋势预测,建立不同类型盆地油气发现趋势预测模型。
(二)预测方法
我国其他海域盆地中高勘探程度盆地以已发现的油气可或探明储量与实际勘探历程及勘探工作量所建立的预测模型,结合新一轮资评计算的盆地油气可或地质,以时间序列、地震工作量序列和钻井工作量序列(每个序列包括逻辑斯谛和龚帕兹两个预测模型,对处于勘探后期的盆地还可增加指数模型)预测今后未来一段时期(2006~2030年)内在一定勘探工作量支持下,盆地内油气储量(可或地质)发现或产量增长趋势。
中低勘探程度盆地使用类比法进行油气储量、产量预测。
(三)预测结果
依据多种预测方法获得的数据,结合对石油勘探储量增长趋势的分析,对预测结果作适度调整,综合给出未来25年其他海域盆地的石油、天然气储量、产量预测趋势,列于表3-1-15。
表3-1-15 南海南部主要盆地每五年年均油气地质储量发现趋势预测表(108t油当量)
注:油气产量和海域其他低勘探盆地油气储量、产量预测结果未附。
六、中国石油大学(北京)趋势预测结果
(一)工作范围
包括81个陆上的Ⅲ类和Ⅳ类盆地。
其中彰武、河套、羌塘、银根、赤峰、民和、伊犁、三江、大杨树、巴彦浩特、鄱阳、百色、保山、景谷、陆良、三水等16个盆地进行了油气储量和产量的预测;
南华北、花海、洛阳—伊川、六盘山、柴窝堡、措勤、伦坡拉、句容—常州、延吉、阜新、楚雄、洞庭、金衢、望江、漠河、清江、胶莱、茂名和库木库里等19个盆地只进行油气储量的预测。
(二)预测方法
建立了以类比法为主,统计法和综合分析法为辅的预测方法和参数体系。对百色、保山、景谷、陆良4个Ⅲ类盆地用统计法进行2006~2030年油气储量、产量增长趋势的预测。使用类比法和综合分析法对我国陆上81个低勘探程度盆地中的一级盆地进行了油气储量和产量预测,对二级盆地进行了油气储量预测。
(三)预测结果
依据多种预测方法获得的数据,结合对石油勘探储量增长趋势的分析,对预测结果作适度调整,综合给出未来25年其他陆上盆地的石油、天然气储量、产量预测趋势,列于表3-1-16、表3-1-17。
表3-1-16 陆上低勘探程度盆地石油发现趋势预测结果表
表3-1-17 陆上低勘探程度盆地天然气发现趋势预测结果表
(四)子项目预测结果汇总
本次预测未包括南海南部盆地,4个子项目的油气储量、产量预测结果汇总如表3-1-18、表3-1-19。
表3-1-18 四个子项目石油储量、产量预测结果统计表(不包括南海南部盆地)
表3-1-19 四个子项目天然气储量、产量预测结果统计表(不包括南海南部盆地)
能耗预测技术
油气储量、产量增长趋势预测的方法大致可以划分为三大类,一是专家评估法,二是统计法,包含时间序列数学模型法和工作量数学模型法,三是类比法。
(一)专家评估法
1.基本原理
专家评估法是指预测者制作油气趋势预测表格,分发给熟悉业务知识、具有丰富经验和综合分析能力的专家学者,让他们在已有资料的基础上,运用个人的经验和分析判断能力,对油气的未来发展做出性质和程度上的判断,然后经过分析处理,综合专家们的意见,得到预测结果。
2.实施步骤
(1)设计油气趋势预测表格。预测表格主要包含油气储量、产量高峰值及持续时间的预测,以及每五年的平均储量发现和产量情况(表4-2)。
表4-2 发现趋势专家评估法预测表
(2)将表格分发给专家进行预测。选择对我国油气状况比较了解,有较高理论水平和丰富实践经验,在油气评价和战略研究方面卓有成效的专家学者。将表发给专家,并附以相关资料,请专家对表中所列事项作出预测与评价,并给出预测依据。
(3)预测结果的分析整理。用统计方法综合专家们的意见。把各位专家的预测结果予以综合、整理、分析,并将结果以图表的形式表现出来。
(二)统计法
统计法主要依据已知的油气储量、产量数据,用各类数学模型,进行历史数据的拟合,并预测未来的发展趋势。统计法包括时间序列法、勘探工作量数学模型法、递减曲线分析法、储量—产量历史拟合法和储量—产量双向平衡控制模型法等(表4-3)。
表4-3 油气发现趋势预测统计法模型分类表
其中,时间序列模型法中的翁氏旋回、逻辑斯谛模型、龚帕兹模型、胡陈张模型、多旋回哈伯特和勘探工作量模型法以及储量—产量双向平衡控制模型法较为常用。
(三)类比法
1.方法原理
所谓类比法是指开展低勘探程度盆地的油气储量、产量趋势预测时,以勘探程度较高的盆地作为类比对象,依据预测盆地与类比盆地在盆地类型和油气地质条件的相似性,设预测盆地投入充足勘探开发工作量的情况下,未来一个时间段内能够发现的油气储量和达到的产量。类比法可分为探明速度类比法和图形类比法。类比法的建立为低勘探程度地区的油气储量、产量增长趋势预测提供了可行的思路和办法。
2.方法种类
(1)速度类比法。以盆地类型为主要划分依据,分别选取松辽、鄂尔多斯、渤海湾、二连、准噶尔、柴达木、吐哈、酒泉、塔里木、苏北和百色盆地作为石油储量发现和产量增长的类比盆地,选取四川、鄂尔多斯、塔里木、吐哈、柴达木、松辽、渤海湾、南襄和百色盆地作为天然气储量发现和产量增长的类比盆地。依据各盆地油气的探明程度与出程度,将以上盆地的勘探开发阶段划分为早期、中期和后期,不同阶段具有不同的油气地质储量的探明速度和可储量的出速度。对低勘探程度盆地进行油气趋势预测时,给定油气储量发现和开始具有产量的起点,类比高勘探程度盆地的探明速度和出速度,预测出未来某一时间单元内(2006~2030年)该盆地油气储量探明状况和产量增长状况。
(2)图形类比法。图形类比法是设在有充足的勘探开发工作量基础上,预测盆地和类比盆地具有相似的勘探发现历程与产量增长过程,预测盆地可类比高勘探程度盆地的储量发现和产量增长曲线,使用类比盆地的模型参数以及预测盆地的量数据,即可得到预测盆地油气趋势预测曲线,进而得到2006~2030年储量和产量的数据。
按照类比标准表所选取的盆地,使用龚帕兹模型分别进行储量和产量数据曲线的拟合,得到40个储量类比图形和产量类比图形,以及相应的图形参数a、b。
3.实施步骤
(1)建立类比标准表:选取勘探程度较高的盆地作为类比盆地,按照盆地类型进行分类,将各盆地的储量发现和产量增长划分为不同的阶段,统计计算各阶段的储量探明速度和产量增长速度,制作类比标准表。
(2)建立类比图形库:根据作为类比盆地的高勘探程度盆地的储量、产量历史数据,用龚帕兹模型进行曲线拟合,得到控制图形形状的参数a和b,分别拟合类比标准表中各盆地的储量和产量曲线,建立类比图形库。
(3)为预测盆地选择合适的类比盆地:预测盆地与类比盆地的盆地类型、地层时代、储层岩性相近,油气地质条件可以类比。
(4)按照类比标准表分别给各预测盆地储量探明速度和产量增长速度赋值,并按盆地实际情况选择对应的持续时间,得到2006~2030年预测盆地累计探明程度、储量以及累计产量。
(5)将预测盆地的量和类比盆地的参数a和b代入龚帕兹公式,得到预测盆地的储量发现和产量增长曲线。
(6)以探明速度和产出速度类比法为主,并考虑图形类比法得到的预测结果,对预测盆地2006~2030年油气发现趋势进行综合分析。
(四)综合预测法
1.方法原理
综合预测法是指以盆地或预测区的潜力为预测基础,分析其勘探开发历程,依据目前所处的勘探开发阶段,确定其未来储量、产量可能出现的高峰值及时间,使用多旋回哈伯特模型,用储比控制的办法,对油气储量、产量进行预测。
多旋回哈伯特模型可表示为:
全国油气评价系统建设
式中:Q— —油田年产量,104t或108m3
Qm— —油田年产量高峰值,104t或108m3;
t——时间变量,年;
tm— —产量高峰年份,年;
i——哈伯特旋回个数;
k——哈伯特旋回总数;
b——模型参数。
用多旋回哈伯特模型预测石油地质储量和油气产量首先要确定哈伯特旋回的个数,除了已出现的高峰,还要预测将来可能出现的高峰个数,这需要掌握丰富的地质资料和勘探开发历程,并对油气田的未来发展趋势有比较正确的认识;然后通过最小二乘法进行非线性拟合,确定单个哈伯特模型的参数,最后将多条哈伯特曲线叠加得到总的预测曲线。
2.实施步骤
(1)油气储量、产量高峰的基本判断。开展盆地油气储量、产量发展趋势预测是以其油气潜力分析为基础的,盆地的量和探明程度、产出程度基本上决定了油气未来储量、产量上升或下降的态势。因此,依据盆地目前所处的勘探阶段、潜力、历年所发现的储量规模、石油公司的“十一五”规划和中长期发展规划以及专家评估法做出的判断,确定盆地的储量发现高峰是否已过,如果高峰已过,则未来的储量发现将呈现衰减的形势;如果尚未达到高峰,则需要判断高峰出现的时间及高峰值,不同类型盆地的储量高峰所处的勘探阶段不同,但一般出现在探明程度40%~60%时。产量高峰的判断还要考虑油气开发状况,一般比储量高峰晚5~20年。通过专家小组会议确定各盆地的储量、产量高峰。
(2)油气储量、产量增长曲线拟合。在确定了盆地储量、产量的高峰后,即可使用多旋回哈伯特或高斯模型进行油气储量、产量曲线的拟合。首先要确定哈伯特旋回的个数,除了已出现的高峰,还要根据未来可能出现的高峰值,选择合适的旋回个数,然后通过最小二乘法进行非线性拟合,精确确定单个哈伯特模型有关高峰值、出现时间及表示曲线形态的参数,最后将多条哈伯特曲线叠加得到总的预测曲线。
(3)用储比控制储量、产量之间的关系。首先对预测期内的储比变化趋势进行预测判断,一般而言,高勘探程度盆地的储比呈现下降趋势,而低勘探程度盆地的储比在储量发现高峰之前快速上升。然后对盆地的储量、产量进行预测,用储比控制法控制储量、产量之间的关系。储比控制法是在对预测期内新增动用可储量的预测基础上,用剩余可储量的储比作为控制条件进行产量预测的一种方法。预测期历年的新增可储量,包括老油田提高收率增加的部分和新增动用储量增加的部分。
国外能耗预测概况
能耗预测技术最重要的就是正算法能耗预测技术的应用。正算法的技术路线是利用现有仿真技术及管道模型研发“正算法”能耗预测软件。经研究分析,“ 正算法”能耗预测软件开发,建议用基于SPS等仿真技术进行二次开发的技术路线。
预测模块应实现根据月度、年度输量给定的输量,自动生成开机输送方案,并预测不同方案的能耗,对油气管道能耗进行自动预测;要具备对燃料费、动力费用预测的功能。预测模块内部应包括“方案自动生成子模块”、“能耗指标折算子模块”、“逻辑判断子模块”等3个功能子模块。“方案自动生成子模块”、“能耗指标折算子模块”、“逻辑判断子模块”等3个功能子模块应通过通信协议与SPS仿真软件联动,实现自动预测能耗的逻辑过程。开发“方案自动生成子模块”,将压缩机机组、泵机组、加热炉的开机方案,作为此子模块的主要输出信息,按照一定的算法,自动生成若干开机方案。开发“能耗指标折算子模块”,将耗能量及能耗指标作为此子模块的主要输出信息。开发“逻辑判断子模块”,根据SPS仿真软件输出的管输介质输量、压力、温度,以及耗能设备功率、转速、负荷等数据,和“能耗指标折算子模块”输出的耗能量及能耗指标,按照既定逻辑判断是否需要继续试,并给出优先挑选哪一类方案进行试算的指向性输出信息。
正算法所实现的能耗预测软件是离线的,即不以实时的SCADA数据作为数据来源进行业务过程的修正。基于“正算法”的能耗预测软件,应以油气管道离线水力、热力仿真计算软件为基础进行开发。能耗预测模块,应实现对天然气管网、成品油管道、原油管道的能耗预测。
正算法预测是基于SPS仿真软件进行二次开发而建立的能耗预测模块。其主要特点:一是运行方案自动生成及初步优选;二是利用SPS对运行方案进行模拟,并将模拟结果转化为能耗数据、燃料费、动力费等。
正算法预测模块的功能结构如图11-3所示:
方案自动生成模块,根据用户输入的管道参数、约束条件,进行方案自动生成并初步优选,形成方案库,为后续进行模拟仿真提供输入基础。
根据管道设备情况,用列举法,即不考虑管道水力热力条件,将管道所有可能的泵组合、压缩机组合等进行列举,形成开机方案的全集。
图11-3 正算法预测模块结构图
在输量一定的情况下,可以通过计算公式计算出所有开机方案的泵(压缩机)、加热炉功率,得到各方案能够提供的总压头和总功率。
在输量一定的情况下,可以通过计算得到管道所需要消耗的总压头、总能耗的最低值,利用该值对方案全集内的方案进行对比判断,从而获得最接近能耗最低值的方案。
方案模拟仿真模块是通过其中的控制模块读取开机方案模块所生成方案集中的指定方案,包括关键设备的启停状态、流量控制值、温度控制值等,并将其写入SPS模型中对应的点,实现对SPS模拟仿真的控制。
逻辑判断分为两种:即可行性判断,判断方案是否有超压、无法翻越最高点等情况,确定方案可行性;指向性判断,判断方案能耗高低,将指向性结果输出到方案生成模块。
能耗折算模块是正算法预测模块中进行数值转换的重要模块,其将SPS输出结果折算为生产单耗、耗油量、耗气量、总能耗等能耗指标。
如图11-4所示,原油管道方案生成用如下流程:
1)管道情况描述。用站场、管道、泵、加热炉、油品5个数据类对这条管道进行表达描述。
2)输入管道输量、分输量、注入量以及管道最低进站温度等必要参数。
3)流量分配,根据输量、分输量及注入量对全线进行流量分配,确定各管段的流量。
4)管段温降计算。用苏霍夫公式计算管道全线的温度分布情况。
5)管段压降计算。用达西公式计算各管段在给定输量条件下所需要消耗的压头。
6)通过3、4、5步迭代确定出管道所需消耗的最低能量。
7)根据管道压头损失情况,确定各个泵站所需要开启泵的最低数量;根据管道设计承压能力,确定各个泵站能够开启泵的最大数量。
8)依据各站开泵的最大、最小数量,进行全线的开泵情况组合,形成方案集,并对各方案的能耗进行计算排序。
9)将方案集中的方案与最低能耗进行对析,初步确定最优方案。
10)将最优方案写入数据库,SPS控制模块取出数据库中的方案,通过事先对好的点,将开机方案对应的指令写入SPS模型中对应的设备,驱动SPS模型模拟方案所指工况。
11)逻辑判断模块读取SPS计算结果,如果需要调整,则返回方案生成模块进行调整(根据产生总压头与管道所需压头进行比较,确定是高还是低;然后将方案的节流量与剩余压头之和同主泵单泵产生压头进行比较,确定是否具备增加、减少泵的条件)。
图11-4 管道方案生成流程图
12)如果不需要,则输出方案到能耗折算模块。
13)能耗折算模块读取SPS模拟数据,计算出该方案设定时间范围内的总能耗和生产单耗,供使用人员参考。
14)对于任何一次完整的预测过程,系统都将自动将其存入数据库,以备后期查询;可按管道查询历史预测结果,其中包含用户输入的数据和计算的结果和开机方案。
下面再介绍一下天然气管道方案生成数学模型。
首先设定目标函数。
天然气管道系统方案生成模块数学模型以最小能耗为目标,其数学表达式为:
油气管道能效管理
式中:S为生产总能耗,kW;Nj为第j个压缩机站的功率,kW;Nc为管网系统中压缩机站总数。
基本约束条件分为进(分)气量约束和进(分)气压力约束。
进(分)气量约束:运营部门购买的天然气只能在一定气量范围内变化。另外,各用户根据自身需要对购气量也有一定要求。即:
油气管道能效管理
i=1,2,…,Nn。
式中:Qi为第i节点进(分)气量,m3/d;Qimin为第i节点允许的最小进(分)气量,m3/d;Qimax为第i节点允许的最大进(分)气量,m3/d。
进(分)气压力约束:天然气运营部门购买的天然气的压力应该限制在一定范围内,同时,用户根据自身需要对管网各分气节点的压力也有一定要求。因此,管道各进(分)气点的压力需满足下式:
油气管道能效管理
i=1,2,…,Nn。
式中:Pi为第i节点压力,Pa;Pimin为第i节点允许的最小压力,Pa;Pimax为第i节点允许的最大压力,Pa。
管道强度约束:设天然气管道系统中管道总数为Np,为了保障管道的安全运行,管道k中的天然气压力必须小于此管道的最大允许操作压力,即:
油气管道能效管理
k=1,2,…,Np。
式中:Pk为第k管道中天然气的压力,Pa;Pkmax为第k管道允许的最大压力,Pa。
下面介绍管道压力降方程。天然气在管道中流动时会产生压力损失,根据气体在管道中流动的连续性方程和动量方程,得出气体在管道内稳态流动应满足的方程为
油气管道能效管理
式中:M为通过管道的气体流量,kg/s;PQ为管道起点压力,Pa;Pz为管道终点压力,Pa;T为气体流动温度平均值,K;L为管道长度,m;D为管径,m;Δh为管道起始端与终端高程差,m;Z为气体压缩系数,按BWRS状态方程计算;A为气体摩阻系数。
管网节点流量平衡约束。在天然气管道任意一节点处,根据质量守恒定律可知流入和流出该节点的天然气质量应该为0。一般地,对于有N。个节点的天然气管网系统,节点的天然气流量平衡方程组可以写为如下形式:
油气管道能效管理
式中:Ci为与第i个节点相连元件集合;Mik为与第i个节点相连元件k流入(出)i节点流量的绝对值;Qi为i节点与外界交换的流量(流入为正,流出为负);aik为系数,当k元件中流量流入i节点时为+1,当k元件流量流出i节点时为-1。
压缩机功率约束。天然气管网系统中每个压缩机站中压缩机的个数和种类都不尽相同,因此,每个压缩机(站)的功率(由于压缩机的特性原因)被限制在了一定的范围内。
油气管道能效管理
j=1,2,…,Nc。
式中:Nj为第j个压缩机(站)的功率,W;Njmin为第j个压缩机(站)允许最小功率,W;Njmax为第j个压缩机(站)允许最大功率,W。
压缩机方程。当气体经过压缩机增压时,应满足方程(11-8)。往复压缩机和离心式压缩机的理论方程如下:
油气管道能效管理
式中:N为压缩机功率,W;ε为压缩机压比,P2/P1;k为压缩机绝热指数;P1为压缩机入口压力,Pa;P2为压缩机出口压力,Pa;V1为压缩机入口处的体积流量,m3/s;ηp为压缩机多变效率,当压缩机为往复式压缩机时,ηp=1。
研究需要优化的运行方案变量,确定出天然气管道系统方案生成数学模型的优化变量为:管道节点处的压力和压缩机(站)的功率。
油气管道能效管理
i=1,2,3,…,Nn;j=1,2,3,…,Nn。
式中:Qi为第i节点流量,m3/d;Pi为第i节点压力,Pa;Nj为第j压缩机(站)功率,W。
用动态规划法对上述模型进行求解,其框图如图11-5所示:
图11-5 方案生成流程
国内油气趋势预测研究现状
目前国际上油气管道能耗预测技术已很成熟,但国际上通常不针对单一的能耗预测功能进行研究、开发软件,而是针对油气管道能耗分析和运行方案优化去研究解决方案,并研发算法和软件系统,使油气管道能耗分析和运行方案优化标准化、自动化,提高精度和效率。
国外经验表明,能耗分析可为运行的持续优化提供重要的技术支持,使天然气管道的运行能耗有不同程度的降低。如20世纪90年代末美国自然(ANR)管道公司用SSI(Scientific Software Intercomp,Inc.)公司的输气管网能效分析优化软件,对其西南输气干线的运行方案进行了能效分析、能耗预测、优化,结果表明运行能耗费下降了1%到5%。2004年,美国艾尔帕索能源(El Paso Energy)公司用规格公司的Flowdesk输气管网能耗分析和预测软件对55,000英里的输气管网进行了持续2年的能效跟踪分析和预测,科学地确定了节能挖潜方向,准确测算出节能潜力,为运行的持续优化提供了有效的支持。统计数据显示,优化后该管网的压缩机组自耗气量比原来降低10%。
国际上与能耗预测相关的解决方案可分为两类,一类以负荷预测类软件为代表的,基于反算法的能耗预测、分析软件解决方案,通常没有优化功能;另一类是以Flowdesk为代表的,综合正算法能耗预测方法和反算法的能耗预测方法的综合性能耗预测、分析软件解决方案,通常内嵌工艺仿真模块,并与运行优化功能相结合。
1.负荷预测类产品总览
负荷预测是一类在线的应用软件,有效结合企业成本和数据库的综合软件。设计为自动的,具有快速和稳定的特性。应用方便,校订现在和未来的数据走向。使企业能够更好地掌握未来的运行。负荷预测软件被誉为数据分析的发动机。
负荷预测一般有三种可用来执行学习的方法。它们是回归法、神经网和基因法。回归法是最基本的分析方法。回归法执行速度也非常快,并且在带有大量数据的个案中将会常常给出更好的结果,可能比神经网或基因法还好。在负荷预测中执行回归法是最小化数据组的平均误差。
神经网是一个比较复杂的分析方法,它能有效地执行所有不同大小的数据组。负荷预测使用神经网来最小化平均误差,当运行时它可创建一个最多包含150个隐藏接点的神经网。神经网的工作方式是将每个预测参数考虑成一个接点。这些接点用权重连结到构成隐藏层的所有接点。从每个隐藏层接点通过权重连接到输出接点。所有权重连结从随机权数和已知值开始通过网络。历史的已知输出值和计算的输出值之间不同,可用来修正权重连结的加权值。这个过程反复重复,直到一个可接受的误差出现或重复次数已达所内设的重复最大值。在负荷预测中,这个过程重复是从1到150可能隐藏层的接点。也有可能负荷预测发现1隐藏层接点是最好的。在此情况下你将看到神经网和回归法中有同样的预测效果。一个隐藏接点系统的结果等于正常回归分析。基因法的复杂性比神经网更复杂一些。基因法所做的是创建一个“代”的神经网,然后它学习那些网。在学习结束的时候,它检查哪些网运行最好,保留下来运行最好的并舍弃其他的。这些网被复制和通过变化一些加权被变化,直到网的数字和原始数字一样。然后这个过程重复,直到最大的代数字或者实现可接受的误差。
使用负荷预测的公司可实施和承担综合预测管理并保证调度中心的安全可靠,和弹性的管道操作。应用负荷预测超级技术可填充中枢系统的预测和管理,掌握管道每天的具体情况和过往的使用情况。设置操作数据并建立管理燃料执行状态,等同于使燃料安全且可以掌握年度燃料预算。操作数据相当于部分流动数据,进口压力,出口压力,数据站操作,外界环境使用预报并解决。使用装载或燃料管道的营业公司可能实施,并且承担派遣工程的联合燃料管理和气体将提供安全、可靠、弹性和竞争管道操作;通过使用专家的技术,例如神经网络和基因算法,气体管道操作公司能实施一个神经网络或基因算法燃料管理系统为它的管道每日操作。这允许操作公司分析它的历史燃料用法作为关键操作数据的建立,并且建立手段测量它的燃料表现,辨认潜在的节约燃料和一个方式控制它的每年燃料预算。操作数据,例如段流速、入口压力、出口压力、驻地经营的数字、四周情况,可用于作为预报因子展望总段燃料用法。
2.综合性能耗预测类产品总览
(1)FIow Desk天然气管道软件
优越的负荷预测、管道模拟、运行优化的综合软件Flow Desk,是一个天然气管道管理、模拟、自动化集成软件套件。它集成了最新和最有效的预测技术,在工业管道可提供模拟和专家系统规则,可用于快速创建天然气业务和商业解决方案。这些工具可用于提高利用天然气管道管理技术,准确预测天然气的输运能力和运输成本,优化天然气管道运行任务,增加收入和利润。其最重要的有下面几个模块:
能耗优化模块。Flowdesk中的能耗优化模块,是一个完整和强大的套件。该产品为管道公司工程师提供精确的能耗优化功能。利用科学的解决方案,用集成和自动化工具,结合业务分析和优化算法,给出在能耗最低下,如何配置复杂的压缩机及管道的其他配置。其基本功能有:确定管道能耗最低时,运行的最优配置;确定哪些压缩机站打开或关闭;确定最佳的压气站设置点;尽量减少燃油消耗和运营成本;选择能耗优化的同时,也保证吞吐量尽量最大化等。
负荷预测模块。GREGG工程公司开发了功能强大的负荷预测模块,将天气、时间、市场力量可能会导致供应和管道系统的需求变化内嵌在系统中。用多种内置的方法进行自动在线离线训练,这些方法主要有,神经网络、遗传算法、回归分析、自定义需求关系、最优化方面跟踪等。系统可以做到每日负荷的总预测,也可以做到24小时预测。
(2)ESI管道软件
ESI公司的实时水力模拟模型PIPELINE MANER提供下列不同的应用模块(其中就有用于改进油/气管线运行安全性并减少运营成本的标准模块):
——管线总量; ——存活时间分析;
——动态泄漏检测和定位; ——关闭时泄漏检测;
——压力监视; ——管线效率模块;
——清洁球跟踪; ——压缩机/泵站优化;
——组分跟踪; ——仪表分析;
——预测模块; ——预测过程模块;
——阴极保护分析; ——操作员培训器;
——负荷预测; ——管线存量管理;
——离线瞬态仿真软件; ——天然气管网商业管理模型;
——基于互联网的管线操作和商业管理集成软件包;
——批量,批量跟踪,批量输送,混油段跟踪;
——DRA分析;——油罐模拟。
以PIPELINE MANER为基础,PIPELINE STUDIO可以模拟操作改变时管道的变化情况,通过研究已制定操作行为的模拟结果,可以得到高质量的决策方案,从而减少维护费用和风险。
PIPELINE STUDIO同样是备受好评的人员培训,可以让操作员不必进入控制室即可观察到脱机环境中操作变化所带来的效果,学习如何预测不同操作在管道上运行的结果,从而全面提高操作质量并且削减昂贵的维护费用。
例如,美国安然油气公司报告说:在他们8500千米气管线上,通过应用上述实时模块,在压缩机燃料上节省了16%的费用,输送能力提高0.3%,并可按用气户要求的输气量按时供气。
PIPELINE STUDIO的基础数据以XML的格式提供,具有无可比拟的优势和灵活性,可以方便地与其他系统交互。一旦在PIPELINE STUDIO中建立了工程学模型,就可以将同样的模型嵌入其他定制的应用程序(也即进行扩展开发),从而提供独一无二的定制解决方案,改进公司的特殊业务流程。例如,可以创建一套应用程序,将输送请求数据与每小时的负荷曲线、SCADA数据相结合,以支持动态的管线分析(常见的例子是在输量不足时确定最优停气方案)。PIPELINE STUDIO在经过修改和执行后,必将成为整个IT战略中的核心部分。
应用与效果
一、研究阶段
国内对油气趋势预测的研究可以分为起始阶段(20世纪80年代)、发展阶段(20世纪80年代至今),未来也将朝综合预测的方向发展。
(一)起始阶段
国内对油气发现趋势的预测研究始于20世纪80年代,中国科学院院士翁文波先生作出了开创性的工作。翁文波先生于年出版的专著《预测学基础》,认为任何都有“兴起—成长—鼎盛—衰亡”的自然过程,油气的发现也有类似的规律,基于此理论思想提出了泊松旋回(PoissonCycle)模型。该模型是我国建立的第一个预测油气田储量、产量中长期预测模型,通常称之为翁氏模型,可以对某一油区、国家或组织全过程的产量进行预测。翁先生于1991年出版了英文版本专著“Theory of Fore-casting”,该书将泊松旋回更名为生命旋回。此后,国内的相关研究机构和学者开展了大量的油气发现趋势的研究,由于统计分析与理论研究工作的深入,在预测模型的建立与应用方面,都取得了显著的成绩。
(二)发展阶段
以陈元千教授为代表继承并发展了翁先生的预测理论,并在油气田储量、产量预测及中长期规划方面得到了广泛应用。1996年,陈元千教授完成了翁氏模型的理论推导,并提出了求解非线性模型的线性试差法。由于原翁氏模型是在模型常数b为正整数时理论推导结果的特例,故将此结果称之为广义翁氏模型。此外,陈元千、胡建国、张盛宗等还提出了威布尔(Weibull)模型、胡—陈—张(HCZ)模型、胡—陈(HC)模型、对数正态分布模型、瑞利模型、广义I型数学模型以及广义Ⅱ型数学模型。黄伏生、赵永胜、刘青年提出了t模型,并由胡建国等完成推导。陈玉祥、张汉亚将经济学中的龚帕兹(Compertz)模型也应用于石油峰值问题的研究。
二、预测模型
综合对比国内外10多种关于石油峰值理论定量研究的模型,大体分为如下3类:基于生命有限体系的生命模型,如:哈伯特模型、广义翁氏生命旋回模型和龚帕兹模型;基于概率论和统计学理论的随机模型,如威布尔模型、对数正态分布模型、瑞利模型和t模型;基于生产实践和理论推理的广义数学模型,如HCZ模型、HC模型、广义I型数学模型和广义Ⅱ型数学模型。
三、研究实例
(一)我国石油储量、产量的趋势预测
1.石油地质储量的预测
国内不同机构或学者利用不同的方法对今后石油探明储量的增长趋势进行了大量的分析,普遍认为未来20年我国石油的年均探明地质储量为7×108~8×108t(表2-2-1)。
表2-2-1 我国石油探明地质储量预测对比表
其中,贾文瑞等用了翁氏生命旋回和费尔哈斯两种模型对今后石油探明储量的增长趋势进行分析。用翁氏生命旋回法测算1996~2010年预计可新增石油探明储量105×108t左右,即年均新增储量为7×108t左右,而且大概在2010年以后,年增探明储量将逐步明显降低。沈平平等人2000年预测2001~2010年中国石油年增探明储量的规模保持在6×108~7×108t。国家石化局预计“十五”期间石油年均新增储量6.44×108~6.9×108t,2006~2015年期间石油年均新增储量为7×108~7.3×108t。钱基在2004年预测,中国的新增石油储量峰值将在18~22年后到来,比美国晚50年左右。从一般含油气区的规律看,产量峰值期比储量峰值期滞后约15~20年。预计中国国内在储量峰值期到来前(2020年)将新增石油探明地质储量160×108~200×108t。张抗、周总瑛利用逻辑斯谛模型、经验趋势法和灰色系统模型预测了近中期我国石油储量增长情况,2001~2005年期间累计新增探明储量35×108~38×108t,2006~2010年期间累计新增探明储量32×108~35×108t。郑和荣、胡宗全2004年预测在未来的20年内每年可新增探明石油地质储量9×108t左右,共可探明石油地质储量180×108t左右。
《中国可持续发展油气战略研究》报告认为,我国石油尚有较大潜力,20年内(2005~2025)储量将稳定增长,发现石油可储量5000×104t以上大油田或油田群的可能性仍然存在。其中,东部地区石油储量增长基本稳定,年新增探明可储量0.6×108~0.8×108t,西部地区年新增探明石油储量可保持在0.5×108~0.6×108t左右。
2.石油年产量的预测
国内对我国石油产量的增长趋势也进行了大量的分析预测,总体认为产量高峰在2×108t左右,高峰出现时间在2010~2020年。
《中国石油发展战略研究》预测我国石油产量高峰期将在2015年前后达到2×108t左右。贾承造2000年预测我国石油产量高峰约1.7×108~2.1×108t左右,高峰值将出现在2010~2020年。
《中国可持续发展油气战略研究》报告预计未来20年石油产量将逐步形成西部和海上接替东部的战略格局,从而保持全国石油产量的稳定增长。预计到2010年,我国东部油区年产油0.89×108~0.96×108t,2020年产油0.76×108~0.85×108t;2010年,我国西部油区产量将上升到0.51×108~0.55×108t,2020年将上升到0.68×108~0.75×108t;预计2010年海域石油产量将上升到0.36×108~0.39×108t;2020年达到0.37×108~0.41×108t。2020年全国实现原油产量1.8×108~2.0×108t是有把握的。
国土部油气战略研究中心2003年预测,2005年我国原油产量1.75×108t,2010年原油产量1.8×108~1.9×108t,2015年原油产量1.8×108~2.0×108t,2020年原油产量1.7×108~1.9×108t。
(二)我国天然气储量、产量的趋势预测
张抗、周总瑛等在2000年总结了国内不同研究机构对中国近中期天然气储量与产量增长预测(表2-2-2、表2-2-3)。
表2-2-2 国内不同研究机构对中国天然气储量增长预测表 单位:1012m3
表2-2-3 国内不同研究机构对中国天然气产量增长预测表 单位:1012m3
李景明等根据1991年以来的天然气储量增长态势,综合考虑中国天然气地质条件和勘探前景,利用翁氏旋回法、龚珀兹法、历史趋势法等预测,2001~2015年共计可新增天然气可储量2.95×1012m3,年均增加可储量1839×108m3。按照2015年年产1000×108m3的产量方案计算,届时中国天然气的储比仍可保持在30∶1以上。天然气储量增长的主体仍然是7大盆地。
钱基预计到2020年,国内可以新增探明天然气地质储量8×1012~10×1012m3。
《中国可持续发展油气战略研究》报告认为,我国天然气比较丰富,正处于勘探早期阶段,大型气田将不断发现。估计2004~2020年共计可新增天然气可储量3.13×1012m3,年均增加可储量1839×108m3。到2020年底我国天然气可储量将达到5.6×1012m3。按照2020年年产1200×108m3的产量方案计算,届时我国天然气的储比仍可保持在25∶1以上。并预测国内天然气产量2010年达到800×108m3,2020年达到1200×108m3。
利用上述处理方法进行叠前深度偏移处理,得到深度剖面,基本解决了崎岖海底的问题,用SRME(海底多次波衰减)方法提高了资料的信噪比,压制多次波效果好,从浅到深各主要反射层显示齐全,能量强弱分明,波组特征清楚,各种干扰和多次波大部分清除,有效波突出,具有较高的信噪比和分辨率,反射层的产状、构造形态显示清楚,断点清晰可靠、归位好,能用于对主要反射层的连续追踪对比解释。
通过地震集处理的攻关,地震资料品质明显提高,这为进一步的地质解释奠定了坚实资料基础。在此基础上,落实了一批构造圈闭,储层预测和烃类检测也都取得了很好的效果,为目标评价提供了保障。
(一)落实了一批构造圈闭
利用二维资料三维工作方式进行叠前深度偏移,所得深度剖面海底崎岖影响基本消除,剖面构造形态清楚,闭合差较小,基本满足地质解释和分析的要求。利用移动平均消除海底崎岖影响的时深转换方法,得到的深度构造图基本能反映地下构造的真实形态,同利用叠前深度偏移技术得到的目的层深度构造图比较,两者形态及高点位置大体相同。不同之处相互修正,得出最终深度构造图,满足勘探精度要求。利用深水长电缆地震资料处理技术,落实了一批崎岖海底的构造圈闭。下面以荔湾3-1和白云6-1构造圈闭为例来说明。
1.荔湾3-1构造圈闭
荔湾3-1构造圈闭处于29/26区块内,距离香港东南方向约290km,距番禺30-1气田约62km,水深1380m,海底崎岖严重。荔湾3-1构造圈闭区域构造位置位于白云凹陷东部斜坡带上,是南部隆起向白云凹陷伸展的鼻状低凸起上一个被断层复杂化的断背斜构造,构造区域二维地震测网约1.5km×1.5km。
荔湾3-1构造圈闭自1990年以来经过中外多方的多轮评估,一致认为它是白云凹陷内最好的构造圈闭之一,是白云深水区实施勘探的首选目标。但荔湾3-1构造圈闭水深超过1300m,而且海底崎岖,由于时深转换方法的不同,多家公司所做的T5层深度构造图相差很大,大的如1999年中海石油研究中心勘探研究院的深度构造图为150km2,小的如ELF公司在1996年所做的深度构造图面积只有35km2。如此大的差异说明了海底崎岖对深度构造图的影响,同时也增加了该目标的不确定性,构造规模大小决定了深水目标是否达到经济门槛。
通过上述方法得出荔湾3-1构造圈闭各层最终深度构造图,图5-11为主要目的层SB23.8的时间和深度构造图。从图5-11可见时间构造图特别是在荔湾3-1构造圈闭的北断块受海底崎岖影响严重。经过我们用此次处理方法后得到的深度构造图,海底崎岖影响基本消除,比较真实地反映了海底下伏地层的构造形态,并和实际地质分析基本相符。
在整体构造面貌上,南断块成为构造的主要部分。在南断块存在两个构造高点,构造的最高点在南断块的南部(而在时间构造图上,高点在南断块的北部)。2006年,LW3-1-1井钻探成功,在构造方面,钻探结果和预测相符。
图5-11 荔湾3-1构造圈闭SB23.8时间—深度构造图
2.白云6-1构造圈闭
白云6-1构造圈闭距离香港东南方向约260km,距番禺30-1气田约45km,距番禺34-1气田约30km,水深1150m,海底崎岖非常严重。白云6-1圈闭区域构造位置位于白云凹陷带,是一个新近系背斜构造,从恩平期的开始,一直位于白云凹陷洼中隆的背景上。构造区二维地震测网1.5km×1.5km。
白云6-1构造圈闭位于白云凹陷最中心的部位,油源条件最好,但它同样处在白云凹陷海底崎岖最严重的部位,地震成像品质很差,信噪比低、连续性差,多次波发育,海底崎岖完全掩盖了下伏地层真实的反射特征(图5-12),要进行目标评价,必须改善此区的地震反射质量。
图5-12 过白云6-1构造圈闭地震剖面04EC2461
前人也对此构造作过多轮构造图,但由于此处海底崎岖非常严重,地震反射质量很差,同相轴很难追踪,因此所做的T5反射层深度构造图相差很大,形态离奇怪异,构造的形态、面积幅度、高点的位置、溢出点的位置等构造基本情况都不落实,只能从构造的发育和剖面上构造隆起的特点粗略判断构造存在。落实此构造的基本情况,消除该目标在构造上的不确定性非常重要。
白云6-1构造圈闭所处的位置比荔湾3-1构造圈闭更接近陆坡,所以海底崎岖的情况比荔湾3-1构造圈闭也更严重,对白云6-1构造圈闭,我们用上述方法进行了叠前深度偏移处理。
通过最终偏移剖面上对层位的精细解释,可以得到白云6-1构造圈闭主要目的层位的各层深度构造图,图5-13为主要目的层SB23.8的时间和深度构造图。
用新方法后,构造的真实形态跃然纸上。白云6-1构造圈闭是一个完整的简单背斜构造,没有断层破坏,面积大,幅度高,和地质分析基本相符。
将三维叠前深度偏移结果和二维条件下进行时深转换的构造图进行比较,可以发现两者构造面积和形态相近,高点埋深和高点位置几乎一致,但在构造的形态方面叠前深度偏移得到的结果更加精细和可靠。
图5-13 二维时深转换和三维叠前深度偏移比较
由此可见,由以前的常规叠后处理转到目前叠前深度偏移处理技术能够改善地层成像品质,消除下伏地层构造畸变,较好地获得崎岖海底区下伏地层真实构造形态,达到目前勘探精度的要求,是降低勘探风险的必然选择。崎岖海底长电缆地震集处理技术,获得了20000km的高质量地震资料,为地质研究、储层预测、烃类检测提供了重要基础资料。
(二)储层预测效果
由于深水区具有少井和无井的特点,针对叠后地震资料,取了对勘探早期较为有效的储层预测技术,即稀疏脉冲反演技术和地震属性分析技术。稀疏脉冲反演技术主要依赖高保幅的叠后地震资料和少量声速测井资料约束进行反演。
1.碎屑岩储层预测
1)无井约束反演
无井约束的反演,实际上就是构建一个接近地下实际地层状况的参数模型,通过构建合理低频模型反演岩性参数,反过来反演结果又可以作为模拟地下状况的地质模型,约束地震反演的低频模型,通过正演和反演的迭代实现无井约束的声阻抗反演。
多年来的白云凹陷勘探实践表明,白云凹陷深水区具有巨大的勘探潜力,白云凹陷为一富生油(气)凹陷,中-上中新统的珠江深水扇及渐新统三角洲沉积是该区的主要储集体系。近年来对23.8Ma以来发育的珠江深水扇及相应的古珠江三角洲沉积条件进行了深入的研究,针对SB13.8时期发育的深水扇,从研究区地震地质条件出发,选几条代表性的地震测线,以99EC1750.5测线为例,建立深水扇层间、层内结构及相关关系,确定无井约束的地震反演的处理流程。
其优点是平行物源方向的测线便于用层序地层格架位置来约束地层的岩性和物性,低频模型的建立是进行无井约束反演的关键。如果对无井约束反演结果作合成地震记录,便可得到接近实际地层状况的正演模型的地震响应。
图5-14 99EC1570.5测线实际地震记录
图5-15 99EC1570.5测线简化的平行物源方向的深水扇声阻抗模型
图5-14为大致平行物源方向的99EC1570.5测线,图5-15是在层序地层格架约束下,对构造的模拟井进行内插外推,得到的99EC1570.5测线理论的地层声阻抗初始模型,用合成声波测井反演,可以得到反演剖面(图5-16)。为了检验无井约束反演的可信度,我们计算了反演结果的合成记录(图5-17),比较合成地震记录与实际地震记录,显然,两者的地震响应特征基本一致,因此,可以认为反演结果是有效的。
2)少井区约束反演
在有井区,将地震资料、测井数据、地质解释相结合,充分利用了测井资料具有较高的垂向分辨率和地震剖面有较好的横向连续性的特点,将地震剖面“转换”成波阻抗剖面,便于将地震资料与测井资料连接对比,能有效地对地层物性参数的变化进行研究,从而得到物性参数在空间的分布规律。在井稀少的情况下,使用基于地震数据的波阻抗反演效果较好。
图5-16 99EC1570.5测线反演的声阻抗剖面
图5-17 99EC1570.5测线声阻抗反演剖面的合成记录
基于地震的反演方法最常见的是稀疏脉冲约束反演,它通过测井约束反演出相对阻抗,再将层位约束下通过测井数据插值得到的绝对阻抗信息(低频信息)通过道融合补充进来,得到分辨率较高的反演结果。
下面以LW3-1-1井为例,我们研究来自2006年集和处理的三维地震数据和2004年集处理二维地震数据,其中三维地震面积约500km2,目的层段的频带范围为3~70Hz,主频为30Hz。在反演工作之前,先研究储层段井曲线的变化规律对井资料进行标准化和环境校正处理(图5-18),保证测井数据真实可信。地震数据要使用经过保幅处理的纯波数据,解释层位要求闭合良好,断层组合好,保证建立的模型可靠合理。在确认这些条件都达到规范标准的情况下,再进行反演工作。
图5-18 LW3-1-1井测井曲线处理结果
首先提取井旁道的子波制作出合成地震记录并与实际地震数据相关,对各目的层段进行精确的标定(图5-19)。用三维地震解释出的层位和标定良好的声波密度测井数据建立合理的低频地层阻抗模型(图5-20),反映巨厚地层的阻抗变化趋势和内部小层的阻抗变化特征。最后要将模型与地震数据反演体结合,以弥补地震数据低频成分的缺失,提高反演结果(图5-21)的分辨率。
图5-19 合成记录标定
图5-20 在层位控制下,用井数据插值的低频成分模型
图5-21 LW3-1地震剖面与波阻抗反演剖面
对储层段的测井解释数据(孔隙度、渗透率)与波阻抗进行交汇分析,可以计算出含气储层的波阻抗门槛值,用该门槛值在波阻抗反演体上对气藏进行全三维追踪雕刻,不仅可以分析出气层的平面分布特征也能计算出气层的厚度。
从有井反演的井曲线处理结果来看(图5-12),此地区的储层具有低波阻抗值的特点,产生低波阻抗值低的原因主要是该区储层含气后的声速曲线值大于上下围岩的声速曲线值差,而且储层具有较低密度值,因而使储层的波阻抗值较围岩的波阻抗值低。从谱分解的结果来看,井曲线处理的结果是可靠的,同时也证明反演的结果符合此地区的地质规律。
此次针对深水少井-无井区碎屑岩的储层预测技术形成了利用深水扇中砂岩、泥岩、含气砂岩的不同岩石地球物理特征,通过深水区源-沟-扇对应关系,结合正演模拟判别富砂扇和富泥扇不同地震响应特征及地震反射结构的深水扇储层地震识别技术与评价方法;形成深水区少井-无井条件下,通过伪井提供低频信息,利用层序地层格架约束层位建立初始模型构造,正反演拟合反复迭代,进行层序约束下的层序地层约束地震波阻抗反演方法,有效地预测了储层分布及物性、含气性等特征。
2.生物礁储层预测
我国南海北部陆坡深水区盆地属准被动边缘盆地,从烃源岩、储层、盖层、圈闭到运聚条件等都具备了形成大型油田的基本地质条件,具有丰富的前景。目前在南海北部陆架东沙隆起区发现了流花11-1生物礁大油田,但是琼东南盆地深水区至今还没有钻井,琼东南盆地已钻区域至今也没有大规模生物礁的发现,钻到的碳酸盐岩储层物性也比较差。琼东南盆地究竟是否存在生物礁油气藏呢?这就需要在琼东南盆地深水区寻找生物礁并了解其发育特征。
北礁西低凸起碳酸盐岩发育区,沉积背景以浅海陆架台地相为主。北礁东低凸起的碳酸盐岩发育区,沉积背景以中中新世离岸坡地相为主。北礁东低凸起构造带,由北礁低凸起、北礁凹陷等单元构成。北礁低凸起是一个远离岸线、陆源沉积作用影响微弱的大型浅水台地,为台地碳酸盐岩发育创造了非常有利的环境条件。
针对研究区的实际情况,在研究的过程中分别利用反演技术和地震属性分析技术对的北礁东低凸起和北礁西低凸起的2004年和2005年的地震测线进行反演和属性分析,关键目的层主要对三亚组和梅山组,基础资料分析2005年的地震数据要好于2004年的地震数据。2005年的地震测线主要在北礁东低凸起上,2004年的测线主要在北礁西低凸起上。
以05e31057线为例(图5-22),该峡谷以南为北礁东低凸起,而南部永乐隆起大部分隆起区在早中新世以后伴随着南海北部陆缘盆地的热沉降才逐渐沉没海底接受沉积,所以除局部高地可提供碎屑物源外,基本上没有碎屑物质供给。北礁东低凸起在梅山组中识别出一套丘状反射,顶面呈丘状起伏,底面近平行反射,内部为断续强振幅,绕射波清楚,应为台地边缘礁相。
根据对琼东南盆地和本地区地质情况的认识,结合前人研究成果、周边钻井资料和周边已知礁灰岩的地震剖面特征分析得知,本地区的梅山组发育有大量的礁灰岩储层,在剖面上具有典型的特征(图5-23)。从地震剖面结合测井曲线分析得到本地区礁灰岩具有高速和高阻的特征。该区的梅山组在连续性上差于宝岛23-1,这也恰好是生物礁灰岩可能富含油气的标志(图5-24)。
以上述工作为基础,在碳酸盐岩有利储层区结合反演特征和分频特征开展单个储层研究工作,我们所标定的梅山1号储层位于梅山组,北临宝岛洼陷,西临北礁凹陷,储层厚度约48m,面积大约为21km2,储层区域由1条北西向的测线和1条北东向的测线组成,该储层具有明显的丘状起伏特征(图5-25)。
图5-22 05e31057线地震剖面特征
图5-23 05E31038测线生物礁地震特征
图5-24 地震属性对比
图5-25 礁灰岩单个储集体预测剖面特征(05e31083线)
图5-26 琼东南盆地深水区生物礁分布预测图
北礁西低凸起周边地区梅山组地层呈现大片的生物礁碳酸盐岩的地球物理特征(包括地震相、瞬时振幅和波阻抗特征)。该区碳酸盐岩分布范围广,横向变化明显。中新世时,北礁凹陷地区南部毗邻西沙群岛海区,北部为半深海沉积环境,因此具有发育生物礁碳酸盐岩的古地理环境。根据其他典型生物礁的地震相和地球物理反演结果并与研究区进行相应对比后认为北礁南凸起周边地区的碳酸盐岩应为台地边缘型生物礁(图5-26)。由于该区礁体分布范围很大,且位于北礁凹陷这一生烃凹陷的上方或紧靠该凹陷,因而具有较大的勘探潜力,很可能是未来几年南海北部取得油气突破的重点区域。
(三)天然气检测
天然气检测主要通过地震属性分析进行,就是将地震属性量化,并转化为储层特征。目前天然气检测最主要的两项技术为吸收和AVO分析。
1.吸收方法检测
地震波的衰减特性除与频率有关外,还随着岩性、孔隙流体类型及流体饱和度的变化而变化,胶结性差的地层对能量的吸收比致密岩石地层强得多,因此,可以通过研究地层介质对地震波的吸收性来确定岩性的横向变化和含油气性,圈定油气藏范围。
在研究的过程中选取了白云凹陷深水区2002~2004年的地震测线为研究区,利用地震波衰减技术进行了储层含油气性预测,来分析深水区少井-无井区天然气检测的应用效果。
从不同层序地层衰减梯度的纵向和平面分布来看,结果有着很好的规律性。从剖面来看(图5-27、图5-28),储层较发育的地方,结果呈连续分布;而在储层发育较差的地方,衰减梯度的结果一般呈点状和连续性不好的方式分布。
图5-27 02ec1573线瞬时子波吸收剖面图
图5-28 LW31002线衰减梯度剖面图
2.AVO 方法检测技术
AVO作为一种含气砂岩的异常地球物理现象,最早在20世纪80年代初被Ostrander发现。这一现象表现为:当储层砂岩含气后,地震反射振幅绝对值随炮检距增大而增大(基于SEG标准极性)。
本区含气层AVO异常明显,表现为明显的第3类AVO异常(图5-29)。经过岩石物理分析,从图5-30上可以看出,密度能很好地区别气层。因为本地区砂岩密度普遍低于泥岩,砂岩含气后,其密度进一步降低,更加低于泥岩,并且到深层,这种性质仍然存在因此,我们得到密度是本区最佳储层预测和烃类检测因子,从密度剖面图(图5-31、图5-32)上可以清楚地看到储层的纵向分布与空间展布,并可以圈定含气性较高的范围。经过叠前反演得到能反演岩性与含气性的泊松比、拉梅常数、剪切模量、体积模量、横波阻抗等属性。综合运用这些属性能进行比较准确的烃类检测,可大大降低勘探风险。
图5-29 LW3-1-1道集AVO异常响应图
图5-30 荔湾3-1圈闭岩石物理分析
图5-31 过LW3-1-1井点密度剖面
图5-32 29/26区块含气区平面分布图
吸收和AVO都是利用储层含气后的各种特征来进行储层预测和烃类检测的技术。吸收主要着重于储层含气后,地震波频率的降低和能量的衰减;而AVO主要着重于储层含气后振幅随炮检距的变化。是一个事物的几种不同表现形式,综合运用吸收和AVO技术来进行储层预测和烃类检测是今后的发展方向。
针对深水区各种复杂条件,发展和应用了深水区天然气检测关键技术,建立了少井或无井条件下的流体分析技术体系,并应用于深水勘探目标的评价,取得了较好的效果。具体如下:
Ⅰ形成了地震多属性分析技术,应用了非线性的地震属性提取方法以及敏感属性分析技术。本区含气层的各种属性特征明显,亮点型振幅异常明显,吸收剖面显示明显,属性分析结果和实钻结果吻合度高。
Ⅱ发展了深水无井少井区AVO分析方法,提出了长电缆高阶AVO异常分析的思路。本区含气层AVO异常明显,表现为明显的第3类AVO异常,在部分地区出现第4类AVO异常。
Ⅲ经过岩石地球物理测试和分析,密度参数是本区最佳储层预测和烃类检测因子。通过叠前弹性波阻抗反演得到泊松比、拉梅常数、剪切模量、体积模量、横波阻抗等属性参数,能很好地反映储层岩性与含气性。
Ⅳ完成了各种烃类检测技术在深水区的应用和集成。综合运用这些技术不但可以得到比较准确的烃类检测结果,同时有助于对深水区圈闭的识别和深水钻探的风险分析,大大降低了勘探风险。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。